Analisis klaster atau pengelompokan adalah bagaimana kita membagi objek ke dalam beberapa kelompok yang mana anggota dari suatu kelompok memiliki kesamaan karateristik, dan diantara kelompok memiliki karateristik yang berbeda. Analisis klaster dapat dimanfaatkan di banyak bidang, seperti segemntasi customer, segementasi image, segmentasi pasar, pengelompokan text, dan bisa juga dimanfaatkan dalam preprocessing data untuk menentukan label dari suatu data yang belum diketahui.
Analsis Klaster termasuk salah satu teknik unsupervised learning. metode unsupervised learning adalah metode-metode yang tidak membutuhkan label data dalam dataset yang kita analisis. Dari beberapa metode klaster, K-means mrupakan metode yang paling sederhana dan paling familiar. Dalam metode K-means kita akan melakukan pengelompokan objek ke dalam k kelompok, jumlah kelompok atau k ditentukan diawal.
Langkah-langakh analisis klaster K-means:
- Menentukan jumlah klaster. Jumlah klaster ditentukan oleh peneliti
- Kemudian menghitung jarak antar objek ke titik centroid. Untuk menghitung jarak kita bisa menggunakan manhatan, euclidien, dan mahalanobis.
- Setelah itu tentukan anggota klaster, jarak yang paling dekat dengan centroid maka objek tersebut akan menjadi anggota klatser.
- Menhgitung titik centroid baru. Dengan cara menghitung nilai rata-rata setiap variabel dari anggota klaster yang dihasilkan di langkah 3.
- Ulangi langkah 2-5 hingga konvergen(titik centroid tidak ada perubahan)
Berikut ini kita akan mencoba untuk melakukan lankah - lankah diatas dengan contoh data berikut:
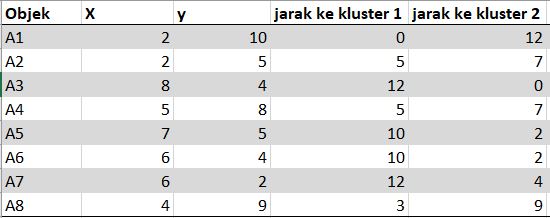
Langkah pertama yang harus dilakukan adalah menentukan jumlah klaster. untuk contoh kali ini jumlah klaster nya 2. kemudian pilih centroid untuk pusat klaster awal. centroid awal yang kita pilih adalah A1 dan A3. kemudian hitung jarak setiap objek dengan centroid yang sudah kita pilih. untuk mengitung jarak kita menggunakan jarak manhatan, ada metode lain untuk mengitung jarak seperti euclidien distance, dan mahalanobis.
Formula Manhatan :
menghitung jarak objek A1 ke titik centorid
|2-2| + |10-10| = 0.0
|2-8|+|10-4| = 12
Menghitung jarak objek A2 ke titik centroid
|2-2|+|5-10|= 5
|2-8|+|5-4|=7
Hitung Jarak objek lainya dengan titik centroid setiap klaster. berikut ini hasil dari menghitung jarak objek ke titik centroid:
setelah itu identifikasi anggota klaster, jika nilai manhatannya paling kecil maka akan masuk ke dalam klaster tersebut.
Hasil klater isterasi 1:
kemudian cari centroid baru dengan cara hitung rata-rata dari setiap variabel dari anggota klaster diatas. rumus rata-rata yaitu jumlah data dibagi banyak data.
centroid baru untuk klaster 1:
x : (2+2+5+4)/4= 3.3
y : (10+5+8+9)/4= 8
centroid untuk klaster 2 :
x : (8+7+6+6)/4 = 6.8
y : (4+5+4+2)/4 = 3.8
Tititk centroid baru:
setelah itu hitung lagi jarak objek ke centroid baru, lakukan langkah langkah diatas sampai konvergen(tidak ada perubahan pada centroid)
Jarak Manhatan dan hasil klaster iterasi 2:
Dari hasil diatas dapat dilihat tidak ada perubahan anggota klaster, yang artinya sudah konvergen. hal ini ditandai dengan centroid iterasi 1 sama dengan iterasi 2.
kesimpulan:
tulisan ini menjelaskan terkait konsep dan implementasi K-mean cluster dengan menggunakan jarak manhatan. kita juga bisa menggunakan metode lainya seperti euclidien distance, dan mahalanobis.
Related Posts: